
Vår førstehåndsopplevelse med AI-bildegjenkjenningsteknologi, Google Lens, har vist at maskinlæring sikkert har kommet veldig langt. Men denne teknologien er foreløpig langt fra perfekt og ikke så smart som vi håpet den skulle være, hovedsakelig fordi tempoet vi trener datamaskiner for å identifisere modeller er sakte. I tillegg krever noen AI avanserte beregninger for nevrale nettverk, og det er absolutt ikke den enkleste oppgaven å lære en maskin.
Med tanke på dette, tok en gruppe Google-forskere det på seg å sette AI-bildegjenkjenningssystemer på prøve og se om de kan bli lurt eller ikke.
Det ser ut til at de har seiret ut siden AI-systemet klarte ikke å gjenkjenne objektet (her, en banan) i prøvebildene, alt takket være et spesialtrykt psykedelisk klistremerke.
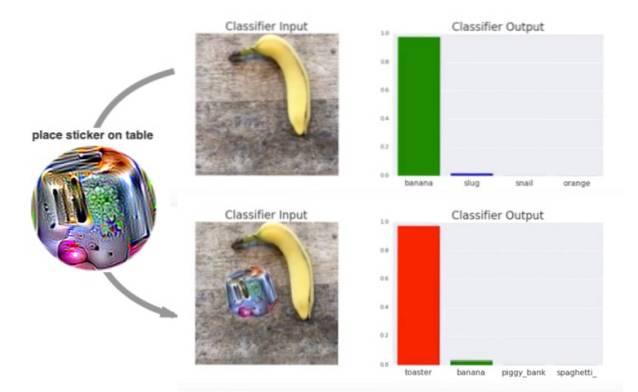
Opprettelsen av disse psykedeliske klistremerker som kan lure bildegjenkjenningssystemer som beskrevet i en forskningsartikkel med tittelen Adversarial Patch, som nettopp ble presentert på den 31. konferansen om nevrale informasjonsbehandlingssystemer i desember 2017. Oppgaven forklarer at forskere trente et motstandersystem (motstander) for å lage små patch-lignende psykedeliske sirkler med tilfeldige former, farger og størrelser for å lure bildegjenkjenningen system.
Mens den vanligste metoden for å lure AI-bildegjenkjenningssystemer, er å endre et bilde ved å legge grafikk til det, bestemte forskerne på Google seg for å lure systemet med psykedeliske design..
Som vist i videodemoen nedenfor, er systemet i stand til å gjenkjenne bananen og til en viss grad brødristeren når du plasserer et normalt bilde ved siden av bananen. Men resultatene er mindre klare når en psykedelisk virvel plasseres ved siden av bananen:
Teamet fant også at en lappet design virker atskilt fra motivet og påvirkes ikke av faktorer som lysforhold, kameravinkler, gjenstander i visningen av klassifisereren og selve klassifisereren.
Forskerne fortsetter med å forklare virkningen av de psykedeliske designene:
Dette angrepet genererer en bildeuavhengig patch som er ekstremt fremtredende for et nevralt nettverk. Denne oppdateringen kan deretter plasseres hvor som helst innenfor synsfeltet til klassifisereren, og får klassifisereren til å sende ut en målrettet klasse.
Mens dette ved første øyekast ser ut som AI-bildegjenkjenning blir lurt, vil dette eksperimentet faktisk brukes til å fjerne inkonsekvensene i systemet. De som jobber innen dette feltet må nå tilpasse seg støyende data som kan inkluderes i motivbildene. Dette funnet kan gi maskinlæringsdrevne systemer en sjanse til å forbedre seg mot lignende bedrag i fremtiden.


